
4 minutos de lectura.
La calidad de los datos es crucial para la divulgación científica. Cada usuario de datos puede consultar el mismo conjunto de datos, pero tener una pregunta de investigación diferente. A partir de tu investigación original puedes convertir tus datos en información útil y de valor para otros usuarios.
Los conjuntos de datos pueden ser muy variados dependiendo de la ciencia objeto de estudio y para darles sentido es necesario contar con un plan y evaluar nuevas formas de pensar acerca del esquema de datos inicial. El aseguramiento de la calidad de datos (Data Quality Assurance, DQA) es el proceso de verificación de la fiabilidad y la eficacia que incluye la actualización de los datos, su estandarización y su control para crear una única vista de los datos. En este artículo te damos algunos consejos iniciales para llevar a cabo este proceso.

1. Organiza
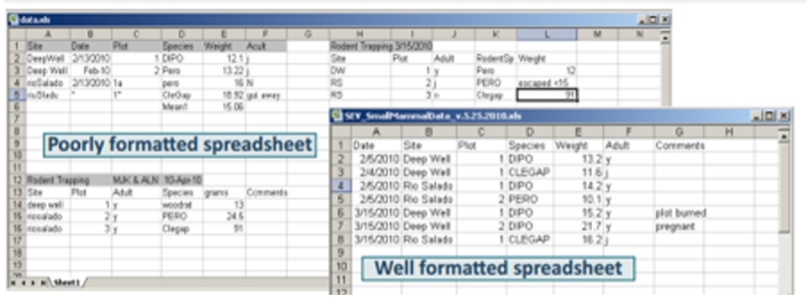
Utiliza técnicas para organizar y recolectar tus datos de manera proactiva. Para organizar nuestros datos, cada conjunto de datos debe tener una variable que identifica de forma única (identificador único) las observaciones. Cada fila nos da la observación particular de cada variable y cada columna nos da la información sobre una característica particular de toda la muestra del conjunto de datos.
Ten en cuenta que un identificador único es una variable que define claramente cada una de las unidades de observación del conjunto de datos. Por ejemplo: números de serie de datos sobre un producto en particular, números aleatorios generados para identificar usuarios que responden una encuesta, etc.
2. Limpia
Mantén tus datos limpios para evitar duplicados y errores a lo largo del ciclo de vida de tu investigación. Recuerda que la falta de calidad puede conducir, entre otros problemas técnicos, a ineficiencias operacionales.
Algunos ejemplos de datos no limpios son:
- Títulos de categorías inconsistentes.
- Valores numéricos en un mismo campo de observación que solo admite texto.
- Valores textuales en un campo numérico, como por ejemplo de código postal.
- Datos duplicados.
- Errores de formato y codificación UTF-8, como por ejemplo caracteres especiales.
- Valores sin referencia.
Algunas recomendaciones para agilizar este proceso:
- Asegúrate que los datos se alinean en columnas apropiadas.
- Verifica que no hay datos faltantes o valores anómalos.
- Busca valores atípicos, para identificar si hubo una posible contaminación de datos.
- Retira los campos que son innecesarios.
- Revisa que los campos no contengan información relevante sobre personas.
3. Da formato a tus datos
Comienza con filas tabulares de datos sin procesar para garantizar que los datos recopilados se encuentren en un formato utilizable para el análisis. Un conjunto de datos se compone de observaciones individuales y de variables y por lo general se muestra en tablas. A los efectos de la usabilidad general, una vez que hayas finalizado con el formato, expórtalo a una hoja de cálculo en forma de archivo “.csv” (valores separados por comas, en inglés comma-separated values), que es un formato universal en donde las diferentes columnas están separadas por comas. Estos archivos se pueden abrir y procesar por programas tipo MS Excel o Google Sheets, así como por paquetes estadísticos más avanzados incluyendo Python, R, Pandas, SPSS o STATA.
En el caso de que tu set de datos tenga un tamaño que no pueda ser visualizado por los programas de hojas de cálculo más tradicionales, será necesario un sistema de gestión de datos (Database Management System, DBMS) que permita visualizar los datos del backend; cuando decimos backend nos referimos a las tablas dentro de la base de datos. En ese caso será necesario asegurarse de que los informes que ejecuten los usuarios, a partir de los datos, sean precisos y considerando que generalmente hay bases de datos múltiples, el objetivo no solo consiste en lo que hay en las tablas, sino también en cómo estas están relacionadas.
Por último
Siguiendo un flujo de trabajo similar puedes garantizar datos de calidad comenzando con la recopilación y organización, seguido de decisiones metodológicas y limpieza de datos, hasta la visualización y el análisis. Esto permitirá presentar un conjunto de datos significativo y fácil de explorar y analizar por parte de otros usuarios. Una vez que hayas implementado estos tres pasos no te olvides de documentar cuál es el significado de las variables dentro de un diccionario de datos.
Por Carolina Huart de la Biblioteca Felipe Herrera del Banco Interamericano de Desarrollo (BID).
Leave a Reply