
8 minutos de lectura.
Si es difícil para una persona encontrar la información que busca, imagina lo complejo que puede ser enseñarles a los algoritmos de inteligencia artificial a identificar información relevante y presentarla cuando un usuario la necesita. Esto es justamente el desafío que encontramos al desarrollar FindIt: una plataforma inteligente que, muy al estilo Netflix, acerca el conocimiento que genera el Grupo BID, tanto a su personal como también a audiencias externas.
Encaramos dos retos centrales en la creación de esta plataforma:
- Ofrecer de manera proactiva recomendaciones de contenido a nuestros usuarios, requiriendo de ellos un mínimo esfuerzo y entregando la información incluso antes de que la pidan.
- Reconocer el nivel de experiencia de nuestros colegas, con base en los datos que ya tenía la organización, para poder recomendar con quien conversar de un determinado tema.
Estamos orgullosos de que logramos vencer ambos desafíos, les contamos cómo.
¿Cómo enseñar a unos algoritmos a simular inteligencia?
Antes que todo hay que pensar como una persona. Cuando necesitas encontrar información sobre un tema puntual, lo piensas en forma de palabras y de conceptos, usando lenguaje natural. Entonces, para que un algoritmo, que es tan solo un conjunto finito de instrucciones, pueda siquiera responder con sugerencias relevantes a una solicitud, primero tiene que aprender a entender lenguaje humano, y aún más difícil en este caso, a comprender la jerga que usamos en el BID.
En la actualidad existen varias tendencias en la implementación de la Inteligencia Artificial, y la del Procesamiento de Lenguaje Natural (PLN) es quizá la más dinámica de ellas. Esta se enfoca justamente en entender, interpretar y manipular el lenguaje humano y en esa línea, nosotros aplicamos 2 metodologías de PLN para diseñar 2 escuelas para algoritmos: una enfocada en ontología, y otra en deep learning.
La escuela enfocada en ontología
La primera lección para nuestros algoritmos es acerca de Taxonomía, que en esencia es una lista jerárquica de términos que permite la clasificación de la información en categorías. ¿Cómo luce una taxonomía? Imaginemos la estructura de un árbol, donde las ramas principales representan las categorías y las ramas secundarias las subcategorías. Aquí pueden ver un ejemplo:
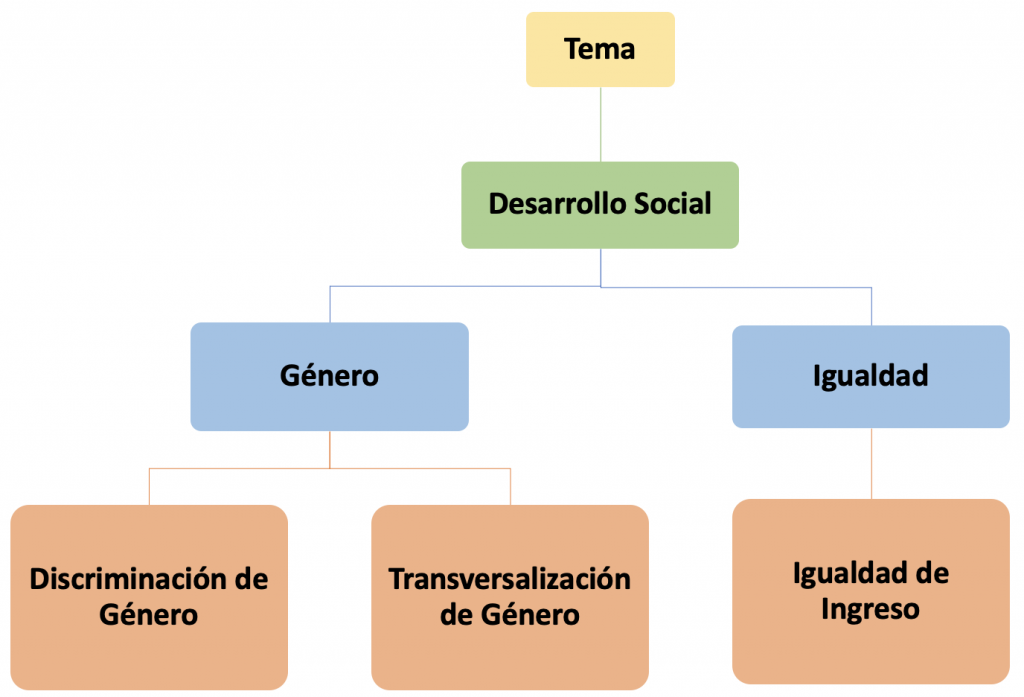
Aunque es compleja, una taxonomía no es suficiente para que nuestros algoritmos entiendan el lenguaje natural humano y tengan la capacidad de recomendar contenido relevante a nuestras audiencias. Creamos, entonces, una Ontología, que es un modelo sofisticado que contiene un conjunto de taxonomías, llamadas clases, que representan familias de conceptos, y que se relacionan entre ellas.
Para tener un mejor entendimiento lo explicamos a través del siguiente diagrama:
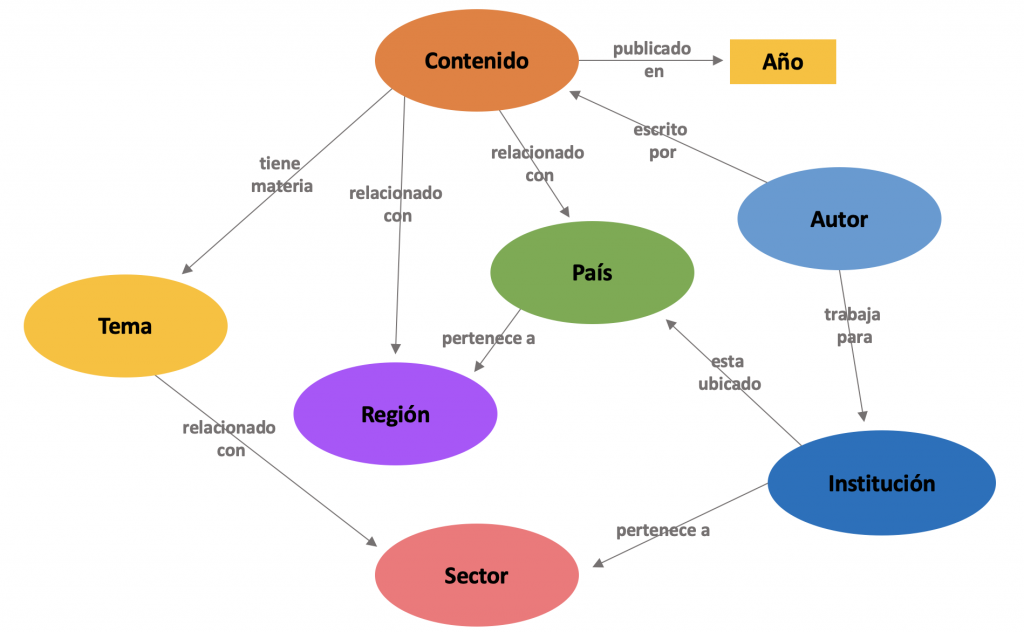
Este diagrama puede tener varias interpretaciones, a modo de ejemplo presentamos la siguiente:
Autor – Trabaja para Instituciones
Autor – Escribe contenido
Contenido – tiene uno o más temas
Tema – Está relacionado a sectores
Instituciones – Pertenece a uno o varios sectores
Contenido – Está relacionado a países y por consecuencia a regiones
En el caso de nuestros algoritmos, la ventaja de un modelo ontológico es que les enseña el lenguaje a través de conceptos, dichos conceptos pertenecen a una o varias categorías bien establecidas, y además tienen atributos que describen sus características. Al recibir un texto nuestros algoritmos pueden identificar el idioma, saben la definición de los términos que reconocen, entienden los sinónimos de los términos, y además hacen una interpretación consistente entre jergas, dialectos e idiomas. Pero más importante, entienden las relaciones entre los conceptos para producir recomendaciones y responder a preguntas complejas como:
- ¿Qué contenido ha publicado recientemente el BID que apunta a la transformación digital en la región de Latinoamérica y el Caribe?
- ¿Estamos trabajando en proyectos que utilizan Drones?
- ¿Qué políticas o acciones se han propuesto para la recuperación económica de la Pequeña y Mediana Empresa en LAC después de la pandemia?
Escalamos este proceso al nivel de 80,000 recursos digitales con la creación de una Gráfica de Conocimiento (Knowledge Graph) donde están desplegadas las conexiones que permiten a nuestros algoritmos hacer sus recomendaciones y aprender de su propia experiencia.
Interesante, pero ¿cuál es el resultado final? Así como Amazon te recomienda productos, FindIt y sus algoritmos infieren que si un usuario visita una publicación sobre iniciativas para aumentar la equidad de género, seguramente estará interesado en otros recursos relacionados al tema y los entrega en la misma interacción. Veámoslo en vivo, ¡haz clic en la siguiente imagen y empieza a vivir la experiencia FindIt!
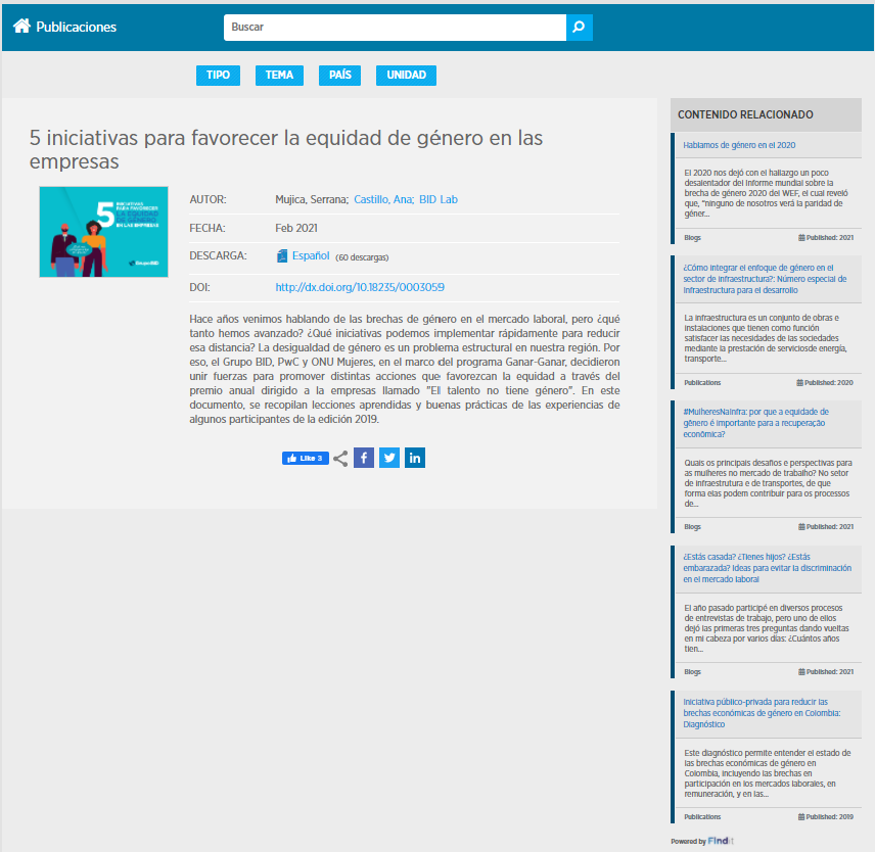
La escuela enfocada en deep learning
En el campo de la inteligencia artificial , el aprendizaje profundo, mejor conocido como deep learning, es una de las áreas que más ha aumentado nuestra capacidad de crear máquinas inteligentes. En esencia, el aprendizaje profundo se trata de la utilización de algoritmos inspirados por la estructura y función del cerebro humano. Estas redes neuronales, así se denominan, procesan grandes cantidades de datos de manera iterativa para descubrir e inferir las conexiones entre los datos. El deep learning es capaz de realizar en segundos un volumen de análisis que a un ser humano tomaría varios meses e inclusive años.
Para aplicar la metodología de la escuela enfocada en deep learning, juntamos más de 2.1 mil millones de palabras escritas en inglés y español sobre el trabajo que realiza el Grupo BID. Estas palabras vinieron de fuentes tan diversas como publicaciones, descripciones de puestos de trabajo, estrategias, y propuestas de proyectos. Analizamos esa gran cantidad de palabras con un algoritmo que genera word embeddings para crear un modelo que revela las relaciones entre conceptos en varias dimensiones. Es importante enfatizar que, más allá del español o el inglés estándar, estas asociaciones reflejan nuestra jerga, nuestra forma particular de hablar en la institución. A modo de ejemplo, presentamos en la imagen de abajo algunas conexiones interesantes que devolvió el modelo:
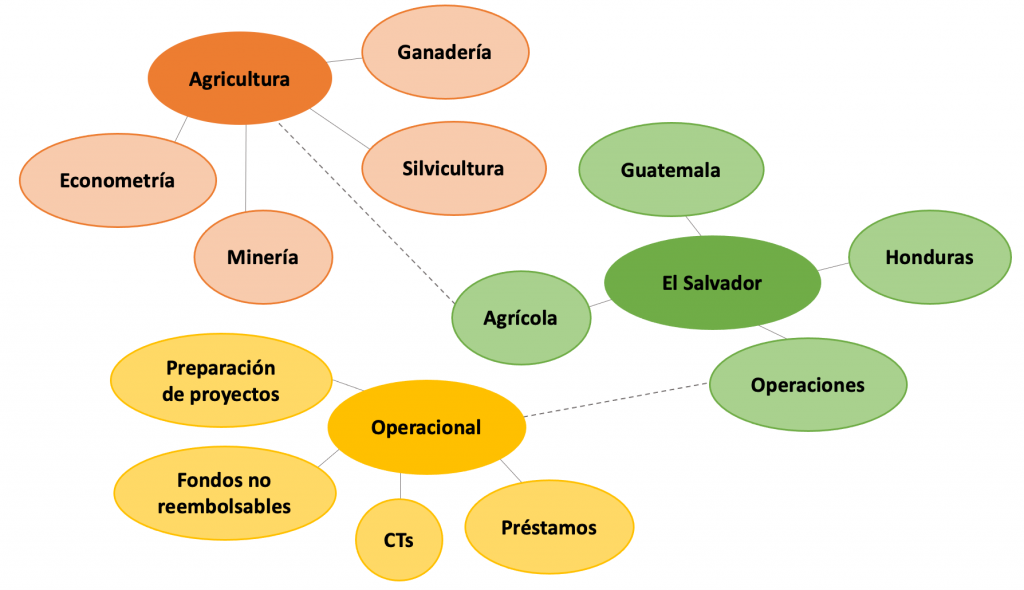
La palabra “agricultura” está relacionada a “ganadería”, “silvicultura” y “minería”, cosa que es entendible, pero el modelo también muestra que la palabra “econometría” está estrechamente conectada a “agricultura”, lo que tiene sentido en el contexto del trabajo que realizamos. “Agricultura” también está relacionada con “agrícola”, que esta cercanamente posicionada al término “El Salvador”, donde apoyamos proyectos agrícolas, que llamamos “operaciones”. “Operaciones” a su vez, está conectada a términos que reflejan cómo nos referimos a nuestro trabajo operativo en el BID, términos como “prestamos”, “CTs “, y “fondos no reembolsables”. Este es un proceso no supervisado, lo que significa que todas las conexiones entre términos están mapeadas por un algoritmo, sin necesidad de curación humana, a diferencia de la escuela enfocada en ontología que requiere supervisión manual regular. Aunque la gráfica de arriba muestra solo tres ejemplos, hay que recordar que el modelo completo está hecho a una escala de más de 2 mil millones de palabras.
Hay muchos usos potenciales para este modelo de lenguaje que revela el mapa de nuestra jerga. En el caso de FindIt, lo utilizamos para traer una nueva perspectiva al análisis de texto que la organización ya tenía sobre su personal, e identificar evidencia de los conceptos más estrechamente relacionados a nuestros colegas para revelar información sobre sus habilidades y experiencias. El resultado final es un buscador de conocimiento tácito, por así decirlo, que permite a los colegas conectarse de manera fácil y rápida para responder a una pregunta, compartir experiencias relevantes o aportar determinadas habilidades a un proyecto o equipo. Todo está impulsado por ese modelo de lenguaje.
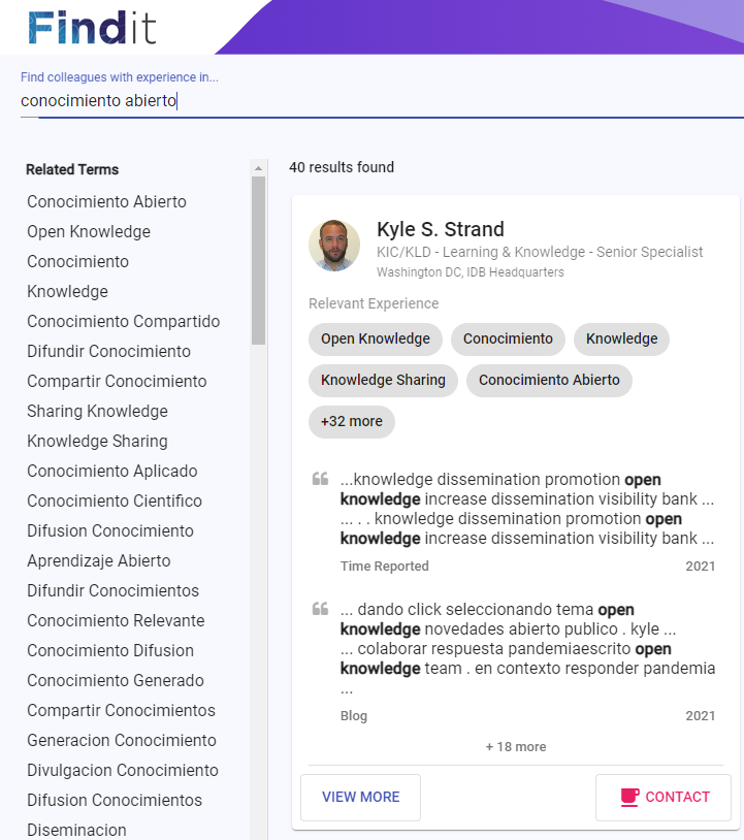
Mira uno de los resultados cuando buscas conocimiento abierto. ¡Buen trabajo FindIt!
Complementariedad: dos modelos es mejor que uno
FindIt se graduó de ambas escuelas: la enfocada en ontología y la enfocada en deep learning. El aprendizaje que obtuvo lo ha aplicado para entender, clasificar, y ordenar recursos digitales, así como para inferir qué conocimiento tiene una persona. Como resultado, ahora, frente a una solicitud puntual planteada en palabras, FindIt contextualiza y sugiere información relevante del universo del conocimiento del Grupo BID. Esta habilidad de conexión entre usuarios y conocimiento aumenta nuestra capacidad de colaboración, y genera mayor utilización del conocimiento, lo que nos lleva un paso más allá en el camino de la transformación digital.
Por Kyle Strand, especialista senior en gestión del conocimiento y Mónica Hernández, consultora en el Sector de Conocimiento, Innovación y Comunicación del BID.
Hola! Soy bibliotecaria y en el área de control de lenguaje trabajamos con modelos ontológicos. Lo nuevo para la materia es el deep learning
saludos