
El procesamiento del Lenguaje Natural (o NLP en sus siglas en inglés) estudia el uso de computadoras para la interpretación y análisis del lenguaje humano (el lenguaje ‘natural’ como es hablado por las personas). Las posibles aplicaciones de NLP para facilitar la gestión de información son amplias y siguen emergentes.
A continuación, presentamos una aplicación de NLP para analizar texto: partiendo de un conjunto de artículos sobre el coronavirus de los blogs del BID, aplicaremos aprendizaje automático para descubrir subtemas dentro de estos artículos. Vale notar que NLP es un campo de estudio amplio y teje relaciones con diferentes áreas de estudio dentro de la inteligencia artificial. Antes de demostrar el ejemplo, vamos a ver un poco más cómo se encajan estos campos diferentes:
¿Qué tiene que ver el NLP con la Inteligencia Artificial?
El siguiente diagrama muestra la relación de NLP con Inteligencia Artificial (AI), Aprendizaje Automático (ML) y Aprendizaje Profundo (DL). Inteligencia Artificial se le llama a la inteligencia realizada por computadoras. El avance de la tecnología y la generación y acopio de grandes cantidades de datos en las últimas décadas resultó en una explosión en el uso de estas herramientas.
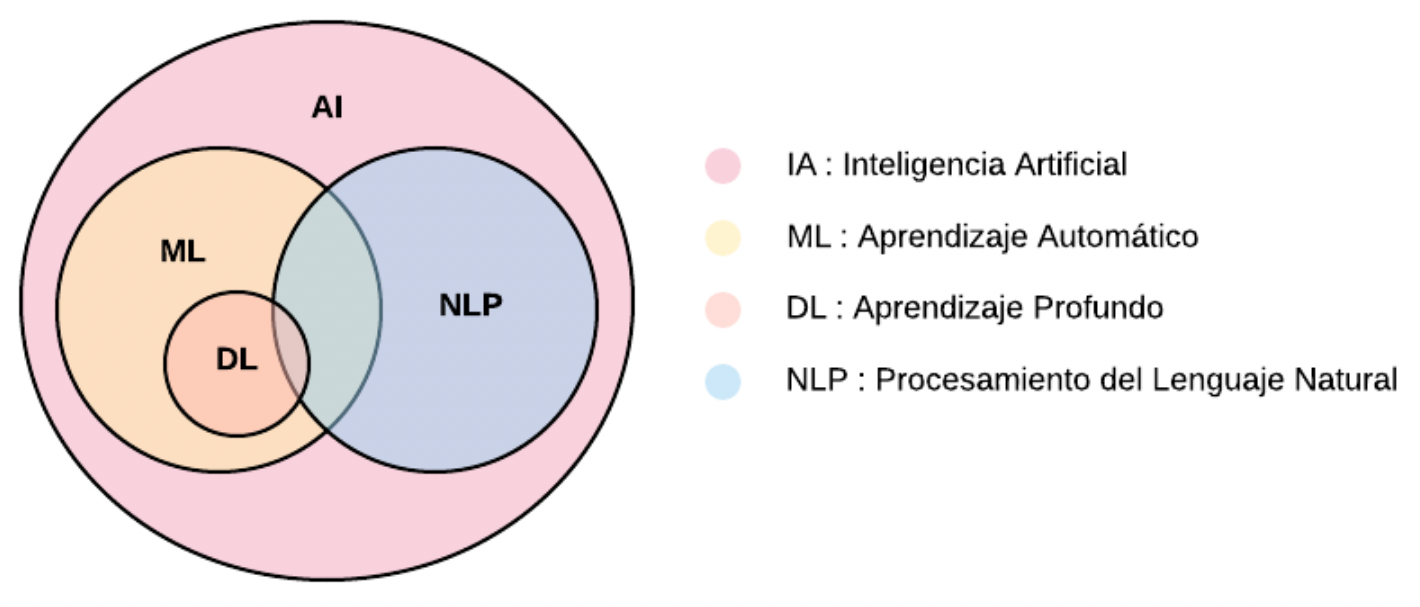
Dentro de la Inteligencia Artificial encontramos lo que se llama Aprendizaje Automático. Este es el uso de algoritmos para encontrar patrones en los datos. Mientras, el Aprendizaje Profundo es un campo dentro de Aprendizaje Automático que utiliza algoritmos llamados redes neuronales. Este es un campo que ha ganado cada vez más terreno dentro de Inteligencia Artificial dado que sus algoritmos continúan mejorando su eficiencia y desempeño y permitiendo realizar tareas con gran exactitud.
¿Y, cómo se aplica el Aprendizaje Automático? Un ejemplo práctico en tiempos de pandemia
Presentamos abajo algunos artículos relacionados algunos artículos relacionados al coronavirus de los blogs del BID. Si bien conocemos el tema común de estos, nos gustaría descubrir qué subtemas podemos encontrar, como por ejemplo educación, infraestructura, comercio, entre otros. Explicaremos paso a paso cómo descubrir estos temas a partir de nuestro conjunto de artículos:
Primero, se extrae y prepara el texto:
Para extraer el texto podemos usar una técnica llamada web scraping dado que nuestro conjunto de documentos son artículos de una página de internet. Existen muchas librerías para aplicar esta herramienta, como BeautifulSoup en Python o rvest en R.
Luego debemos pre-procesar el texto. Estos son pasos para limpiar nuestro texto de ruido y estandarizar nuestro texto para que sea fácil de comparar. Algunos de estos pasos incluyen quitar las puntuaciones, transformar el texto a minúscula, o eliminar palabras frecuentes usadas en el lenguaje como preposiciones, artículos, etc. que por sí mismas no aportan mucha información, además de usar la raíz de las palabras.
Para ilustrar cómo funciona este proceso, tomemos como ejemplo uno de los artículos de coronavirus mencionados anteriormente.
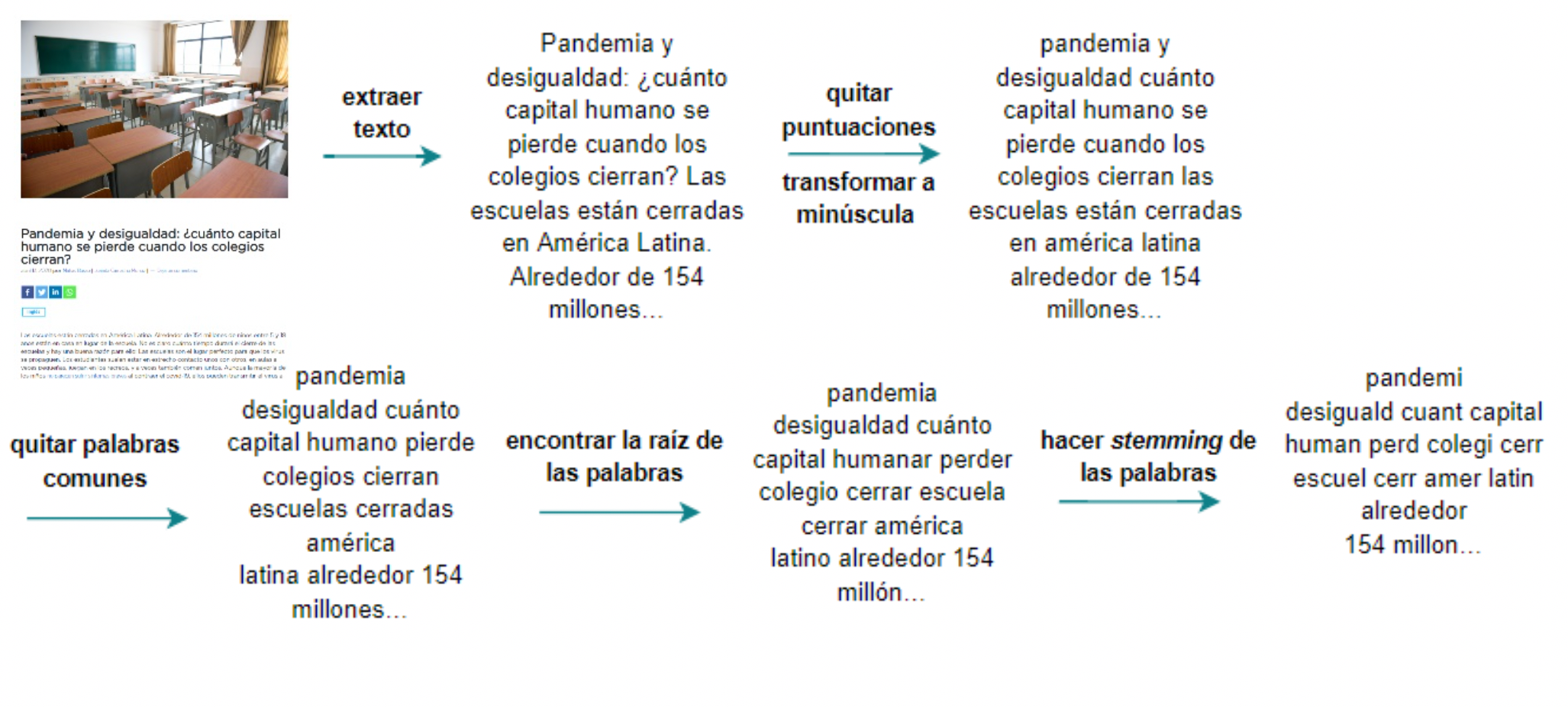
Es importante aclarar que no existe una receta infalible de pre-procesamiento de texto. Estos son solo algunos de los pasos comunes en el análisis de texto tradicional. Existe una amplia discusión en el área acerca de si algunos de estos pasos son realmente necesarios o si estamos perdiendo información valiosa para nuestro análisis al realizar esta limpieza. Depende mucho del texto que tenemos y el análisis que queremos hacer. Por ejemplo, si nuestro objetivo es hacer una nube de palabras para visualizar un texto, quitar las palabras comunes como preposiciones es importante. Por otra parte, si queremos clasificar sentimiento del texto usando algoritmos de redes neuronales, quizás estas palabras agreguen información y será mejor mantenerlas.
Segundo, el texto se convierte en una representación numérica:
Una vez que limpiamos nuestro texto, procedemos a aplicar algoritmos de aprendizaje automático para clasificar el texto. Dado que los algoritmos son ecuaciones matemáticas que entienden números, primero debemos conseguir una representación numérica de nuestro texto.
Hay diversas formas de representar texto con números. Uno de los modelos más simples se llama bolsa de palabras o bag of words (BoW) como es su nombre en inglés. Este modelo consiste en crear una bolsa o lista de palabras que existen en el conjunto de nuestro texto, en este caso nuestros artículos del coronavirus, y asociar cada palabra con cada uno de nuestros documentos. Para esta asociación podemos simplemente marcar si una palabra se encuentra en el texto o no, podemos contar las veces que aparece la palabra en el texto, entre otros. Este tipo de representación de texto si bien es simple, dado que ignora el orden de las palabras y la forma gramatical, nos permite ya realizar análisis complejos muchas veces con resultados robustos.
Debajo mostramos cómo haríamos esto para nuestro conjunto de artículos:
- Primero extraemos todas las palabras que se encuentran en el conjunto de documentos
- Luego construimos una matriz donde las columnas son cada una de las palabras que se encuentran en el conjunto de documentos y en las filas indicamos cuántas veces aparece esa palabra en el documento.

A esta matriz se le llama matriz de términos y documentos.
Tercero, a clasificar:
A partir de esta representación ya estamos listos para clasificar nuestros documentos por temas. Una técnica comúnmente utilizada se llama Topic Modeling o modelaje por temas. Esta es una técnica de aprendizaje automático no supervisado que nos permite descubrir temas abstractos presentes en nuestro conjunto de documentos. Se le llama no supervisada dado que no conocemos los temas a priori y no es posible usar esa información para entrenar nuestro modelo, nuestro objetivo es descubrir qué y cuántos temas podemos extraer de nuestros artículos.
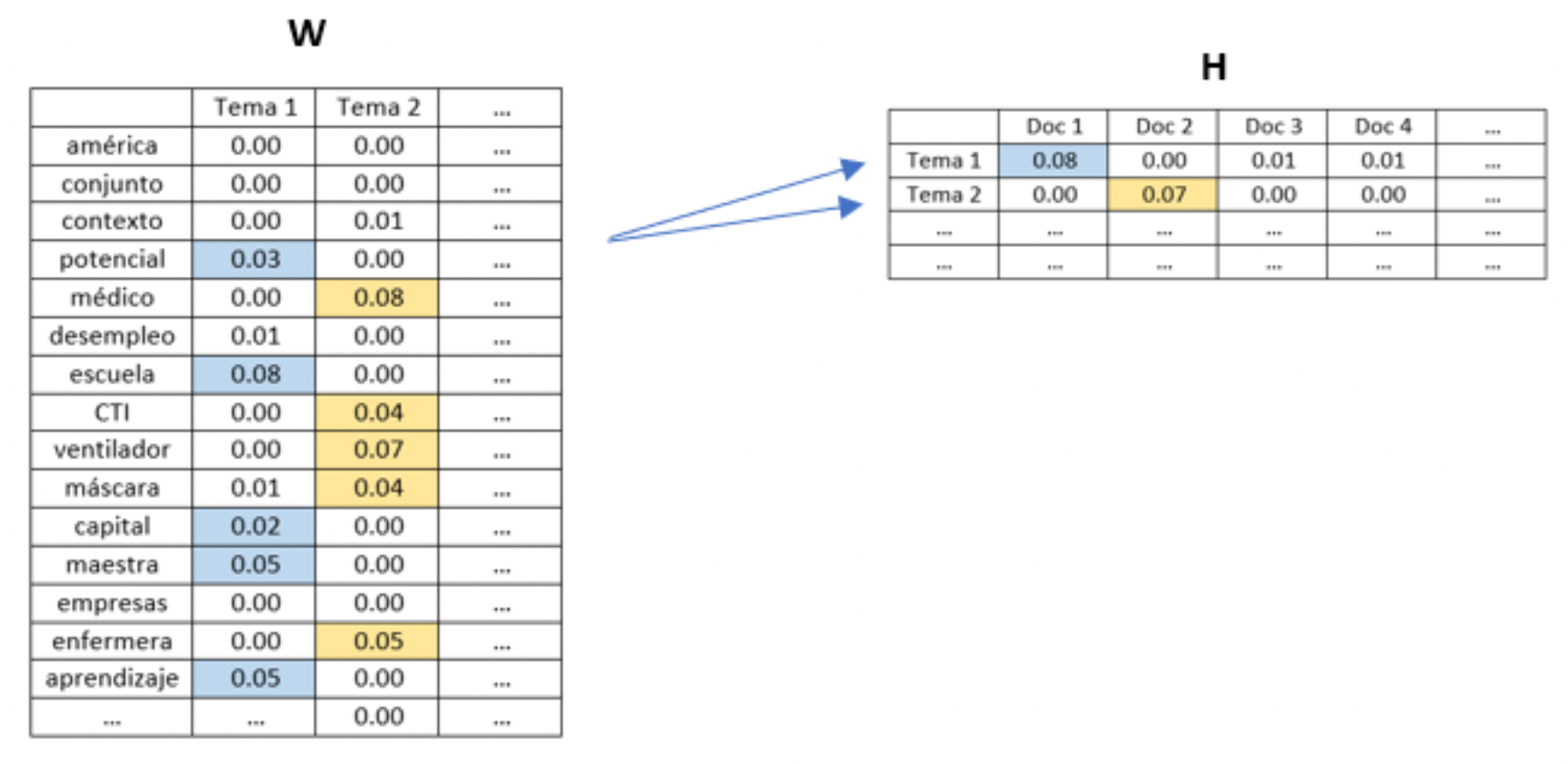
Una de las técnicas usadas para este tipo de modelos se llama Factorización no Negativa de Matrices o NMF como en su sigla en inglés. Este artículo explica los detalles técnicos de cómo funciona este método, pero resumidamente NMF consiste en una descomposición matricial con la propiedad de que las matrices no tienen elementos negativos. Partiendo de nuestra matriz de términos y documentos aplicamos NMF lo que nos permite descomponer la matriz en dos matrices, una que muestra la relación entre los temas y las palabras (llamada matriz W) y otra que muestra la relación entre los documentos y los temas (llamada matriz H). De esta forma podemos identificar las palabras más importantes para cada tema y a partir de ahí deducir de qué se trata cada tema.
En nuestro ejemplo, mirando con detenimiento la matriz W notamos que las palabras potencial, escuela, capital, maestra, y aprendizaje son importantes para el Tema 1 en cuanto las palabras médico, CTI, ventilador, máscara, y enfermeras son importantes para el Tema 2. Por lo que podemos pensar que el Tema 1 tiene que ver con educación y formación y el Tema 2 tiene que ver con hospitales y los servicios de salud. Luego pasando a la matriz H podemos identificar para cada documento qué temas son importantes.
Un desafío al aplicar esta técnica es que el número de temas es un parámetro que debemos pasarle al modelo. Si no conocemos cuántos temas aproximadamente se encuentran en nuestro grupo de documentos podemos probar diferentes números y evaluar los resultados. También existen métricas que nos permiten evaluar cuál número de temas mejor representa nuestros documentos, este artículo explica una de estas métricas.
¿Qué te parece las posibilidades que ofrece la inteligencia artificial? ¿Se te ocurren aplicaciones de estas técnicas para tu trabajo diario?
Por Bertha Briceño y Eugenia Fernandez del Sector de Conocimiento, Innovación y Communicación del BID.
Saludos le escribe Johanna Sànchez , me visto su blog por lo que quisiera de su ayuda de facilitarme LINK sobre temas de PNL con Inteligenica Artificial.
hola tengo una duda, de un corpus llamado reuters lo limpie, lematize, quite cerradas y signos que no son ascii, porsteriormete tengo ya mi bolsa de palabras pero quiero hacer la matriz de correlación, pero es una matriz enorme, como lo puedo hacer con tantos datos?? y no me interesa descartar alguno pero es necesario?? y como lo hago? es que no encuentro ejemplo alguno.