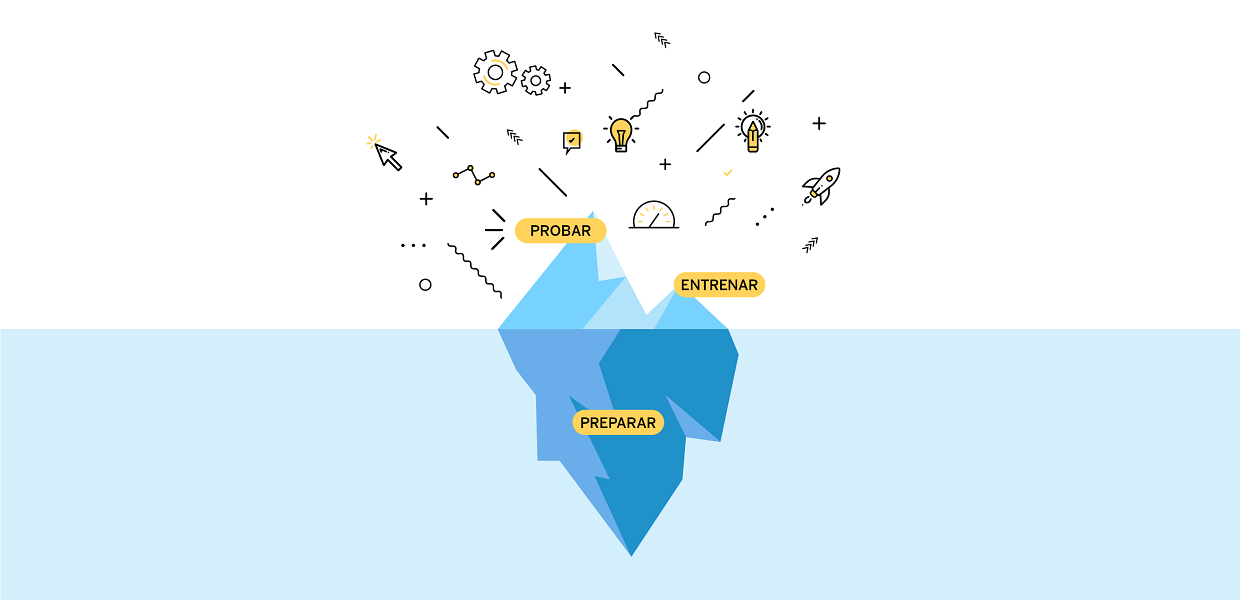
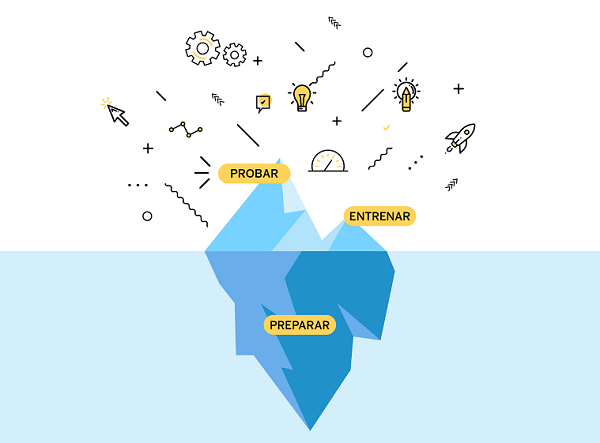
Cuando nos preguntamos cómo funciona la inteligencia artificial, a cualquier nivel, nos damos cuenta de que todos los proyectos de IA se podrían describir como proyectos de datos. Para apoyar esta consideración sugerimos una simple analogía: un iceberg. Elegimos esta comparación porque creemos que un proyecto de IA se podría dividir en tres fases principales: 1) Preparar los datos relevantes al proyecto, 2) Entrenar el algoritmo (o los algoritmos) y 3) Probar los algoritmos entrenados.
El objetivo de esta comparación es poder desmitificar un poco lo que implica trabajar con Inteligencia Artificial. Las técnicas de inteligencia artificial, como el aprendizaje automático, el aprendizaje profundo y el procesamiento del lenguaje natural no son mágicas, y gran parte de su éxito, si no la mayor parte, depende de la extensa preparación de datos que se requiere. Estimamos más más de la mitad del esfuerzo de un proyecto exitoso de IA es el aquel dedicado a preparar los datos. Esto, suponiendo que no se haya limpiado y preparado previamente un conjunto de datos adecuado, lo cual es muy probable si estás utilizando datos de su organización para este efecto, y por primera vez. Sin embargo, a pesar de este esfuerzo considerable, el trabajo de preparación de los datos es un trabajo crítico que en gran medida no se ve, al igual que la mayor parte de un iceberg que se encuentra invisible, debajo del mar. Como tal, la complejidad de esta parte del proceso no siempre se aprecia, ya que no siempre se refleja en los resultados visibles de un proyecto, de la misma manera que solamente una parte, relativamente pequeña al resto del iceberg, sobresale de la superficie.
¿Alguna vez has utilizado un asistente de voz, como Alexa, Siri o Google Home? Imaginemos una interacción con Google Home y exploremos una visión general de lo que sucede durante cada una de estas fases.
Fase 1) Preparar los datos relevantes
Google Home funciona mediante la comprensión de los comandos de voz para tomar acciones apropiadas, como responder una pregunta, configurar un temporizador o controlar algún dispositivo conectado. Para que este tipo de resultados sean posibles, la primera fase, la preparación de los datos, debe consistir en actividades tales como:
- recolectar millones de grabaciones de voz de una amplia gama de registros;
- limpiar el sonido de las grabaciones eliminando el ruido de fondo y similares;
- normalizar las grabaciones a un único formato de audio como mp3;
- etiquetar adecuadamente las grabaciones;
- otras actividades relacionadas.
Por último, los datos deben separarse en al menos dos grupos: un grupo que se usará en la fase 2 de modelar el algoritmo (datos de entrenamiento), y otro grupo que se usará para probar el algoritmo ya entrenado en la fase 3 (datos de prueba).
Para una organización como Google, imaginamos que todas las tareas relacionadas con esta fase se llevaron a cabo durante años, a través de un talentoso equipo de ingenieros y desarrolladores que ganan su sueldo para enfrentar este desafío en el transcurso de múltiples iteraciones y actualizaciones de productos. Además, para las grandes empresas de tecnología, los datos son su negocio, y es por eso que tienen acceso a cantidades masivas de datos relevantes para organizarlos en conjuntos de datos de entrenamiento sólidos y conjuntos de datos de prueba para un desarrollo exitoso de sus productos. Sin embargo, a pesar de todo esto, como consumidores, hemos experimentado las imperfecciones de estos dispositivos en un momento u otro, donde una o más de una palabra fue mal interpretada por un asistente de voz, o en donde una imagen no fue reconocida por algún escáner inteligente.
Ahora, si comparamos estos condicionamientos respecto a los recursos necesarios, versus los datos disponibles para el investigador común que trabaja con IA, comenzaremos a comprender la magnitud de la fase de preparación de datos y su importancia en el proceso general del desarrollo de algo funcional.
Fase 2) Entrenar el algoritmo
En esta fase, elegiremos primeramente qué algoritmos vamos a entrenar. Imaginemos que cada uno de estos bloques de plastilina es un tipo de algoritmo: el bloque rojo representa una regresión lineal, la naranja representa k-medias, la púrpura representa redes neuronales y la turquesa representa las máquinas de vectores de soporte.

¿Qué sucede durante el proceso de entrenamiento? Probablemente hayas escuchado la expresión que es necesario encontrar el algoritmo con el mejor ajuste. Bueno, aquí es donde la analogía de la plastilina te ayudará a entender esta metáfora. Durante el proceso de entrenamiento, cada algoritmo se moldea a los datos de entrenamiento al encontrar patrones en los datos, por lo que al final de la fase entrenamiento, los algoritmos podrían verse así:
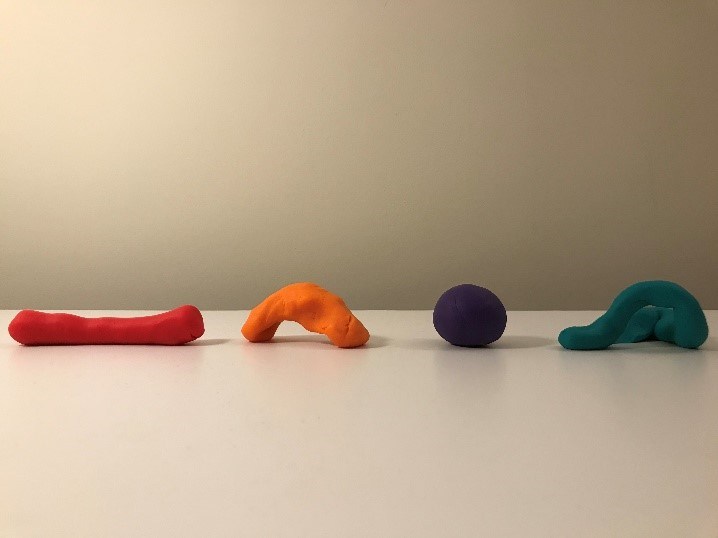
Fase 3) Comprobar los algoritmos entrenados
En la fase 3, que también llamamos la fase de prueba es donde a cada uno de los modelos entrenados se les proporciona los datos de prueba para ver cuál de ellos es el que da la mejor predicción. Para continuar con la analogía de la plastilina, si decimos que un resultado exitoso significa “tener la capacidad de rodar”, podríamos entonces concluir que de todos los algoritmos entrenados que están en la imagen anterior, las dos figuras que podrían rodar, serían las de color rojo y púrpura. Sin embargo, la figura que va a poder rodar de manera más eficiente es evidentemente la más redonda, la púrpura. Asimismo, en el caso de Google Home por ejemplo, un resultado exitoso significaría brindar una respuesta adecuada a un comando de voz.
Si los resultados obtenidos en la fase de prueba necesitaran ser mejorados, se diría que se pueden elegir dos caminos: 1) cambiar el algoritmo o 2) adicionar nuevos y relevantes datos a nuestro proyecto. Te recordamos que este es un proceso iterativo, pero en general la secuencia sigue las tres fases del Modelo Iceberg.
Finalmente te comentamos que hay muchas otras consideraciones al momento de diseñar e implementar un proyecto que utiliza Inteligencia Artificial. Nuestra esperanza es que esta simplificación a la que hemos denominado el Modelo Iceberg pueda serte útil para enmarcar el enfoque general de tu próximo proyecto, así como para comunicar el trabajo que se da lugar detrás del escenario o volviendo a nuestra analogía, el trabajo que está debajo del agua.
¿En qué proyectos IA estás trabajando?
Por Kyle Strand y Daniela Collaguazo del Sector de Conocimiento, Innovación y Aprendizaje del BID
¿CÓMO SE COMPARA UN ICEBERG AL FUNCIONAMIENTO DE LA INTELIGENCIA ARTIFICIAL?
Que interesante que temas que parecen complejos, sean explicados en forma tan sencilla, de tal manera que al leerlos alimenta nuestra base de conocimiento, comprensión, y así uno se motiva a explicarlos a otros.
Mis sinceras felicitaciones.
interesante articulo, me gustaria conocer mas al respecto, gracias
Al utilizar analogías y un lenguaje sencillo, la comprensión del tema de IA, es simple y de gran aporte para aplicar a las organizaciones
Que buen articulo me gustó su forma de comparar algo complejo con algo simple y explicarlo de forma clara sin caer en tener que simplemente decir ‘existen algoritmos para eso’
Kyle, gran artículo.
Así como lo mencionas, la IA y el análisis de datos nos llevan a conocer en detalle y a profundidad la correcta identificación de los clientes; a través de la comparación que planteas, logramos entender las cualidades y ventajas de la misma.
Últimamente indagué acerca del uso y beneficios que puede brindar la IA en diferentes sectores económicos, te comparto el link por si deseas conocer más sobre esto; https://www.grupodot.com/es/inteligencia-artificial/casos-de-exito/.
Excelente articulo. Muy diferente a cuantos he consultado.