
Guest post by Dwight Knell, Program Lead at the Credibility Coalition
As awareness grows about the importance of establishing credible information, so do concerns about how this credibility is communicated on content traveling around the web.
The Internet has offered a platform to truly democratize the spread of information and sharing of knowledge. Decreased barriers and costs to publishing, increased social connectivity and sharing of information in real time, global movements for openness, and the collaborative authoring of resources like Wikipedia, are all observed benefits of the information age. But what happens if that information cannot be trusted?
The Misinformation Problem
By now we have all heard about “fake news” and attempts by spoilers to willingly spread misinformation that deceives and misleads the public. However, in addition to the most deliberate misinformation efforts, there are also various shades of gray, in the form of opinions packaged as facts, research which lacks rigor, hyperbole, misattributions, and logical fallacies. These challenges and more contribute to an uncertain information landscape.
Many solutions are being attempted, but the scale of the misinformation problem is so large that any single effort can only provide partial alleviation. A holistic approach is needed to balance the roles of reputation systems, fact-checking, media literacy, revenue models, and public feedback and how they can all influence and contribute to the health and integrity of the information ecosystem. Simply rating an article as “credible” is not realistic; as information consumers, we need to understand what parts of it are credible and how the conclusion about its credibility was reached. As information producers and distributors, we must understand how to communicate credibility effectively, given different intentions behind different styles of content.
Framing a holistic approach for credible information standards
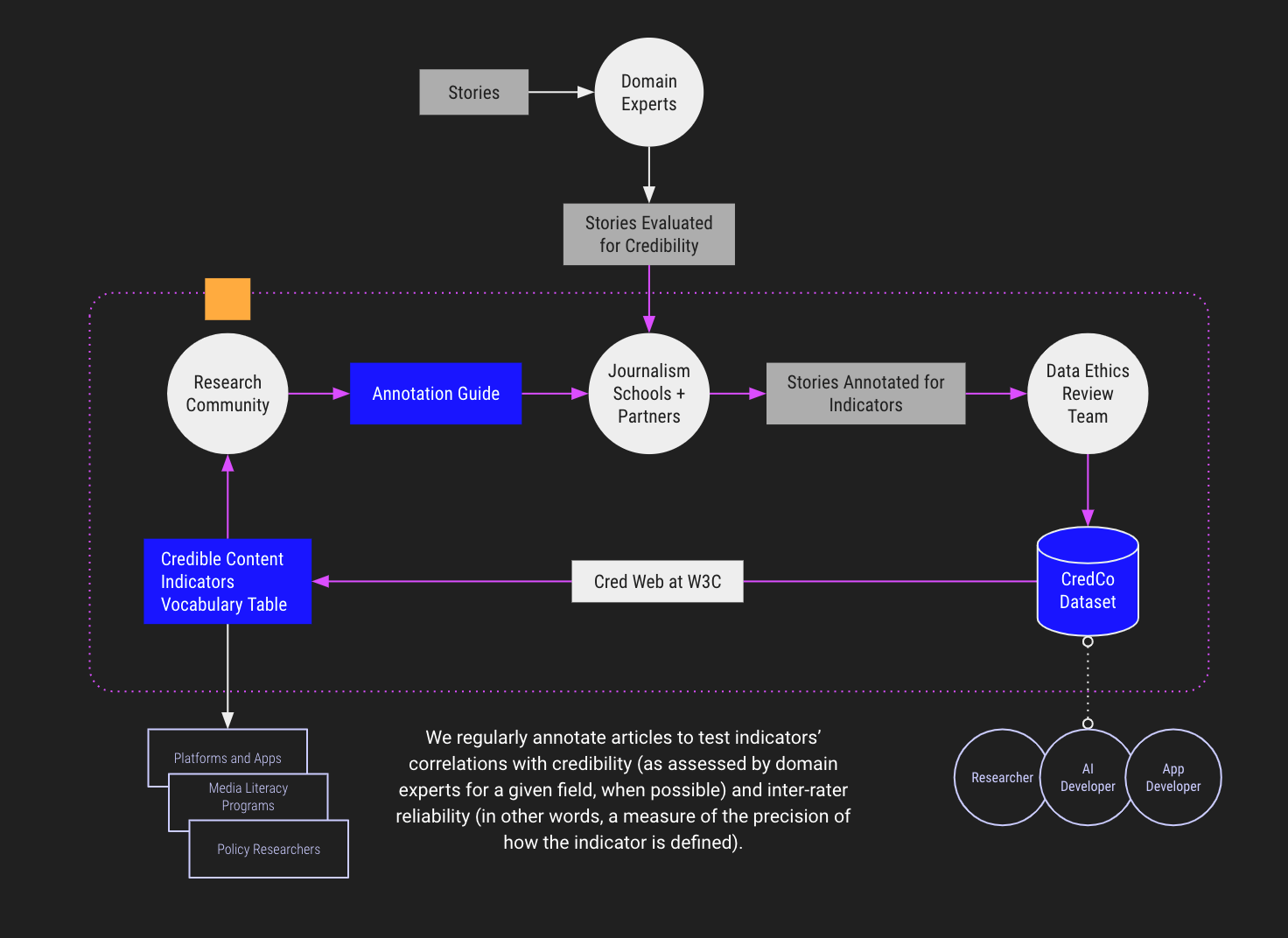
The Credibility Coalition (CredCo) is an interdisciplinary community including technologists, journalists, and academics committed to improving information ecosystems and media literacy through transparent and collaborative exploration. CredCo provides the world’s leading community and infrastructure for generating and validating high-quality open data sets for nuanced indicators about content credibility. We have received funding from initiatives including the Google News Initiative, Knight Foundation, and Mozilla, and work with the W3C Credible Web Community Group to ensure the data is interoperable, specific and understood by researchers, data scientists, platforms and artificial intelligence companies.
Our efforts are currently framed around three main questions:
- Assess: Can we agree on the indicators for reliable information online?
- Scale: Does assessment work at both small and large magnitudes?
- Apply: How can the implementation of credibility standards inform effectively?
Step 1: Assessing Content for Credibility
Can we agree on the indicators for reliable information online? The following lists call out some attributes that at CredCo we think warrant further assessment when determining an article’s credibility. These can be categorized by content signals – determined by the text or what’s inside the article – and context signals – which can be determined through consulting external sources or article metadata and raise questions about who is hosting, sponsoring, or endorsing the content.
Content signals
- Title Representativeness: Article titles can be misleading or opaque about the topic, claims, or conclusions of the content.
- “Clickbait” Title: defined as a certain kind of web content that is designed to entice its readers into clicking an accompanying link, such as “cliffhangers”.
- Quotes from Outside Experts: Is there outside feedback from independent experts to provide support for the conclusions drawn in an article?
- Citation of Organizations and Studies: Are citations included to add context or enhance the credibility of claims?
- Calibration of Confidence: Does the author make absolute claims or use of tentative propositions to acknowledge their level of uncertainty and allow readers to assess claims with appropriate confidence?
- Logical Fallacies: Poorly constructed but tempting arguments including the straw man fallacy (presenting a counterargument as a more obviously wrong version of existing counterarguments), false dilemma fallacy (treating an issue as binary when it is not), slippery slope fallacy (assuming one small change will lead to a major change), and other misleading techniques.
- Tone: Are there exaggerated claims or emotionally charged sections?
- Inference: When correlation and causation are conflated, the implications can be dramatic, for example in medical trials.
Context signals
- Originality: If text is duplicated from elsewhere, was attribution given?
- Fact-checked: We limited our consideration to organizations vetted by a verified signatory of Poynter’s International Fact-Checking Network (IFCN).
- Representative Citations: how accurately the description in the article represents the original content of any cited or quoted sources, such as articles, interviews, or other external materials.
- Reputation of Citations: For scientific studies, there are at least some existing public measures such as impact factor, despite their documented issues.
- Number of Social Calls: Most publications depend on social networks and viral content to drive traffic to their site. That said, a high number of exhortations to share content on social media, email the article, or join a mailing list can be an indicator of financially motivated misinformation.
- Number of Ads
- “Spammy” Ads
- Placement of Ads and Social Calls
Step 2: Developing standards for information credibility with data
Using the previously discussed criteria, does assessment work at scale? At an individual level, results may vary and ultimately appear to be subjective. There are structures, processes, and data needed to enable the participation of organizations, experts, and non-experts in issues of information quality.
In order to build on a more data-driven content evaluation process, CredCo uses a framework to evaluate content that seeks to complement the role of interpretation by researchers, platforms, or automated systems which may be carried out independently. This methodology combines manual annotations by “non-experts” and “experts” to aggregate testing data for possible automation purposes.
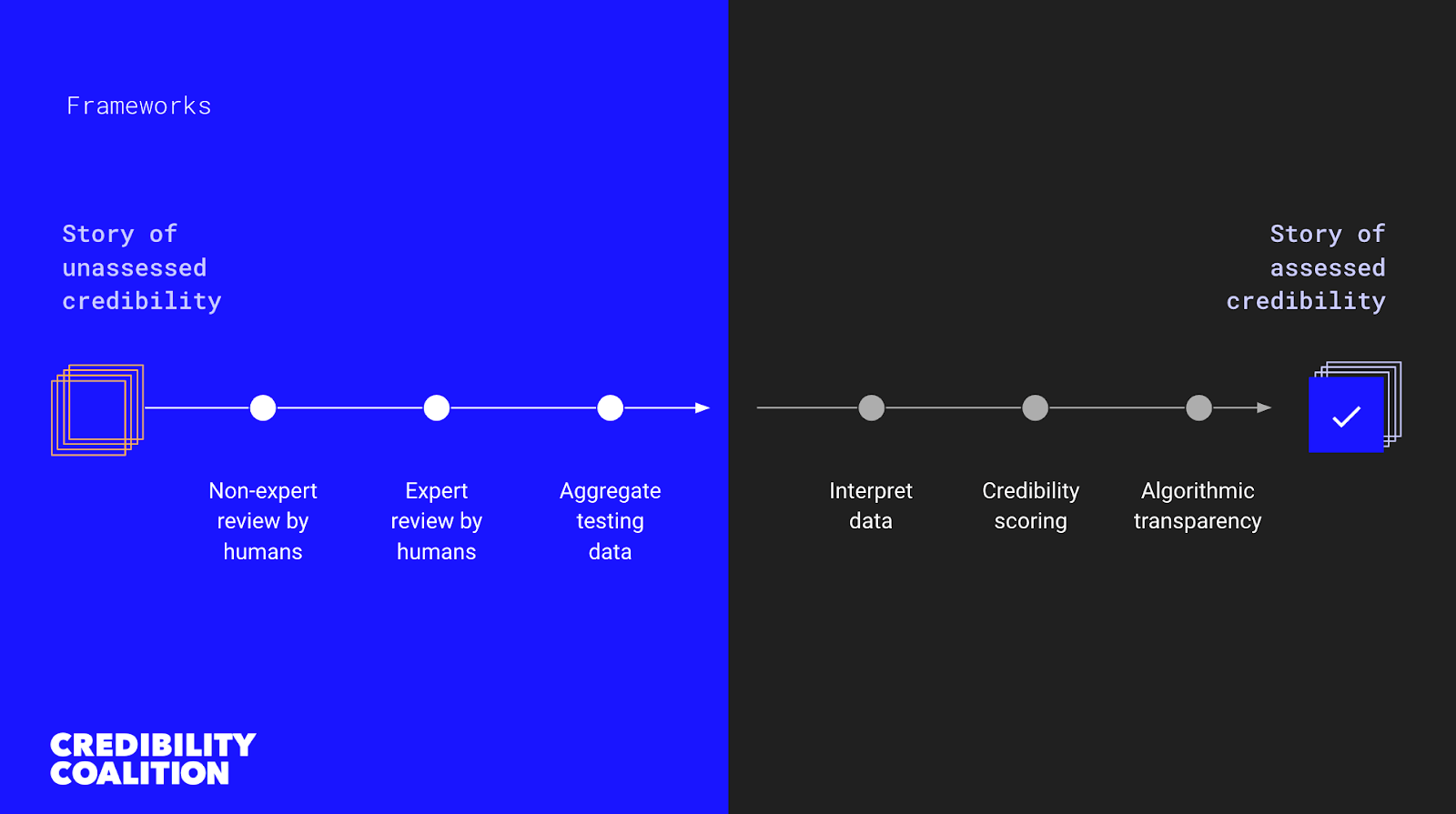
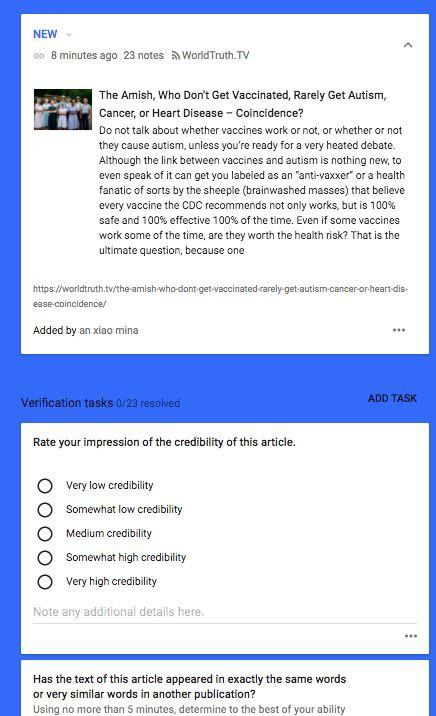
We have experimented with multiple annotation tools in the past, but our annotators primarily perform their work on the platforms Check and Hypothesis. Check gives annotators a simple, straightforward way to review and mark up articles. An example of what Check looks like is below:
Hypothesis allows users to annotate articles in situ on the web. An example is here:
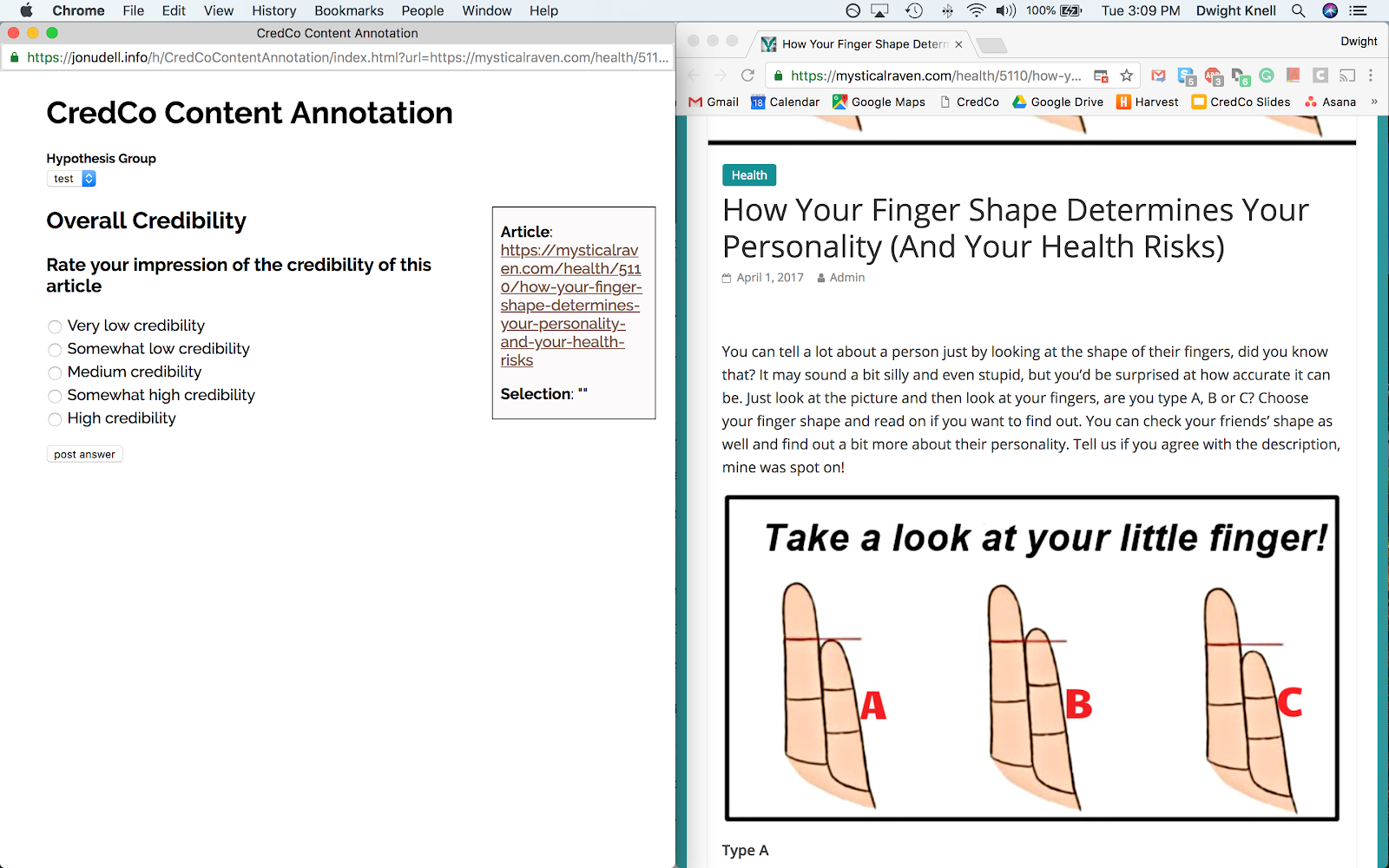
Annotators mark hand-selected articles based on specific content signals as well as context signals discussed previously.
Recognizing the complexity of developing standards, we approach them through rigorous research. We have three major outputs: (1) an annotation guide that can be used for future studies and that can inform larger studies for annotation, (2) a developing, licensed data set of findings, and (3) a vocabulary document developed with the W3C Credible Web Community Group. Recognizing that our information landscape is constantly changing, each of these outputs is regularly updated and developed.
Step 3: Thoughtful application of information credibility standards
How can the implementation of credibility standards inform effectively? One way to start getting at the complexities around separating the credible from the questionable elements of a news post is to think about how to express informational quality as a nutritional label, like this one, originally designed by Clay Johnson:

The label includes markers to differentiate fact from opinion, possible commercial or political influences, and a list of sources. As Matt Stempeck described it while studying this issue at the MIT Center for Civic Media, “…the goal is to make information about the news available to individuals who would like to benefit from it. The rollout of FDA nutrition labels on food packaging in 1990 in the United States did not force individuals to eat differently, but it did provide critical dietary information for those consumers who sought it.”
We think this model will prove useful in helping develop universal credibility standards as well as allowing the public to understand our work in a simpler way. At the same time, it avoids complete censorship or a polarizing value assessment of the content, letting opinions stand as opinions in context.
How do you determine if information online is credible? Leave a comment below.
Leave a Reply